Cricket Match Results Forcasting
INFO 523 - Spring 2024 - Project Final
Step 1: Exploratory Data Analysis
Here, we first carried out Data Preprocessing where we merged the match_data and match_info files, then carried out Exploratory Data Analysis by using pairplots to find correlations between different variables, if any. 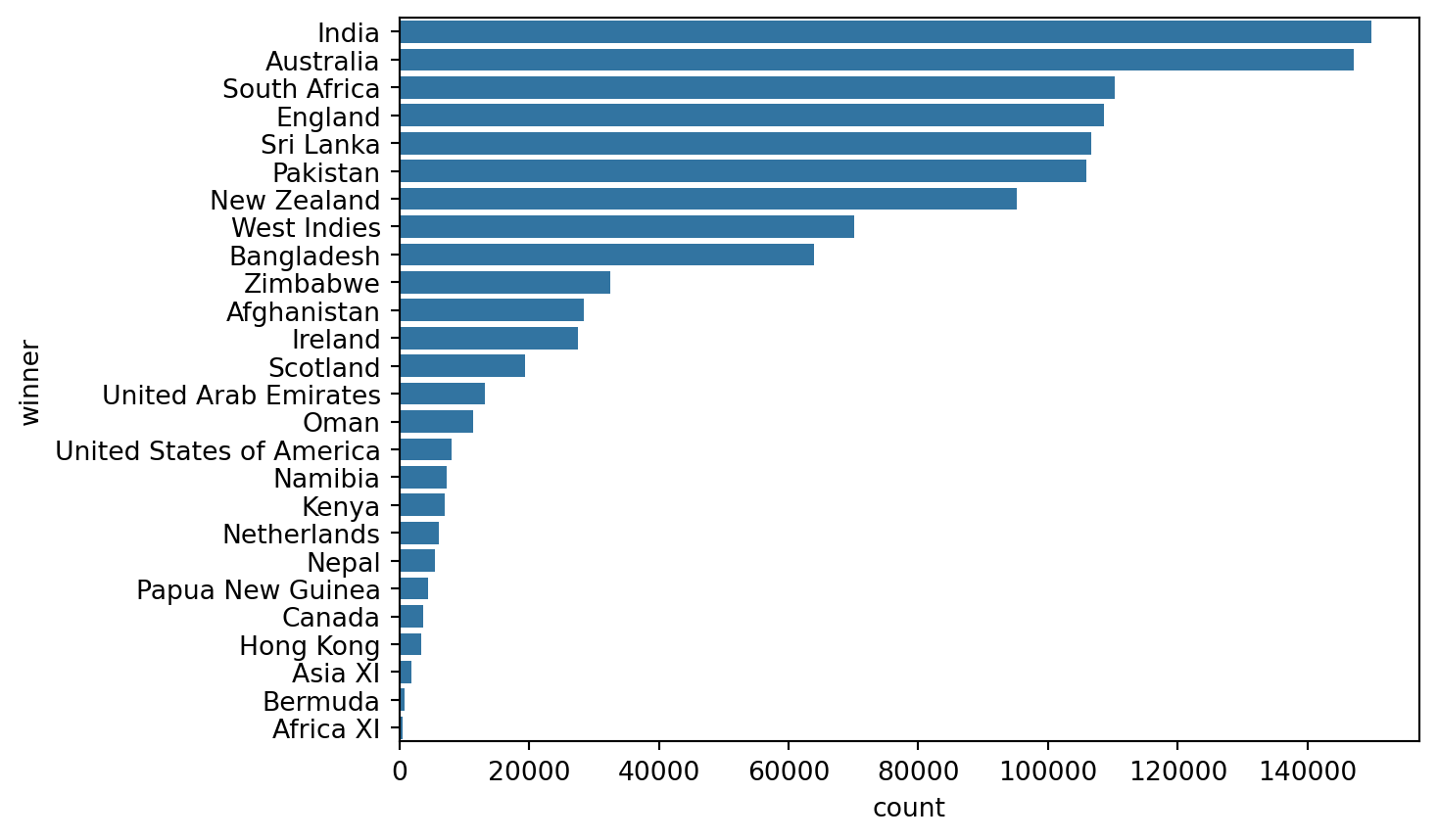
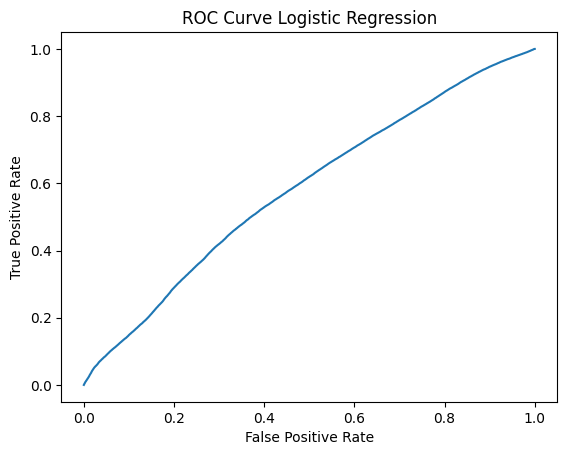
Logistic Regression
From the results of Logistic regression, we observe the accuracy and precision of this model is around 55% and the area under ROC curve is also around 0.5. As these metrics show that this might not be the best model, we move forward and train another model.
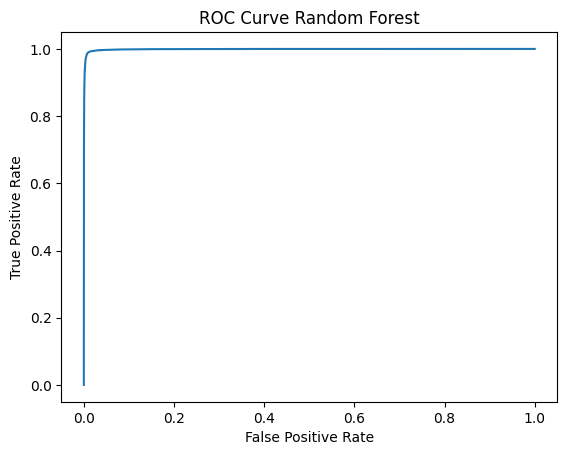
Random Forest Classifier
Now we take the Random Forest Classifier, as we observe the accuracy and precision of this model is around 96% and the area under ROC curve is also around 0.96. These metrics clearly show that this is the best model, so we move forward with this model.
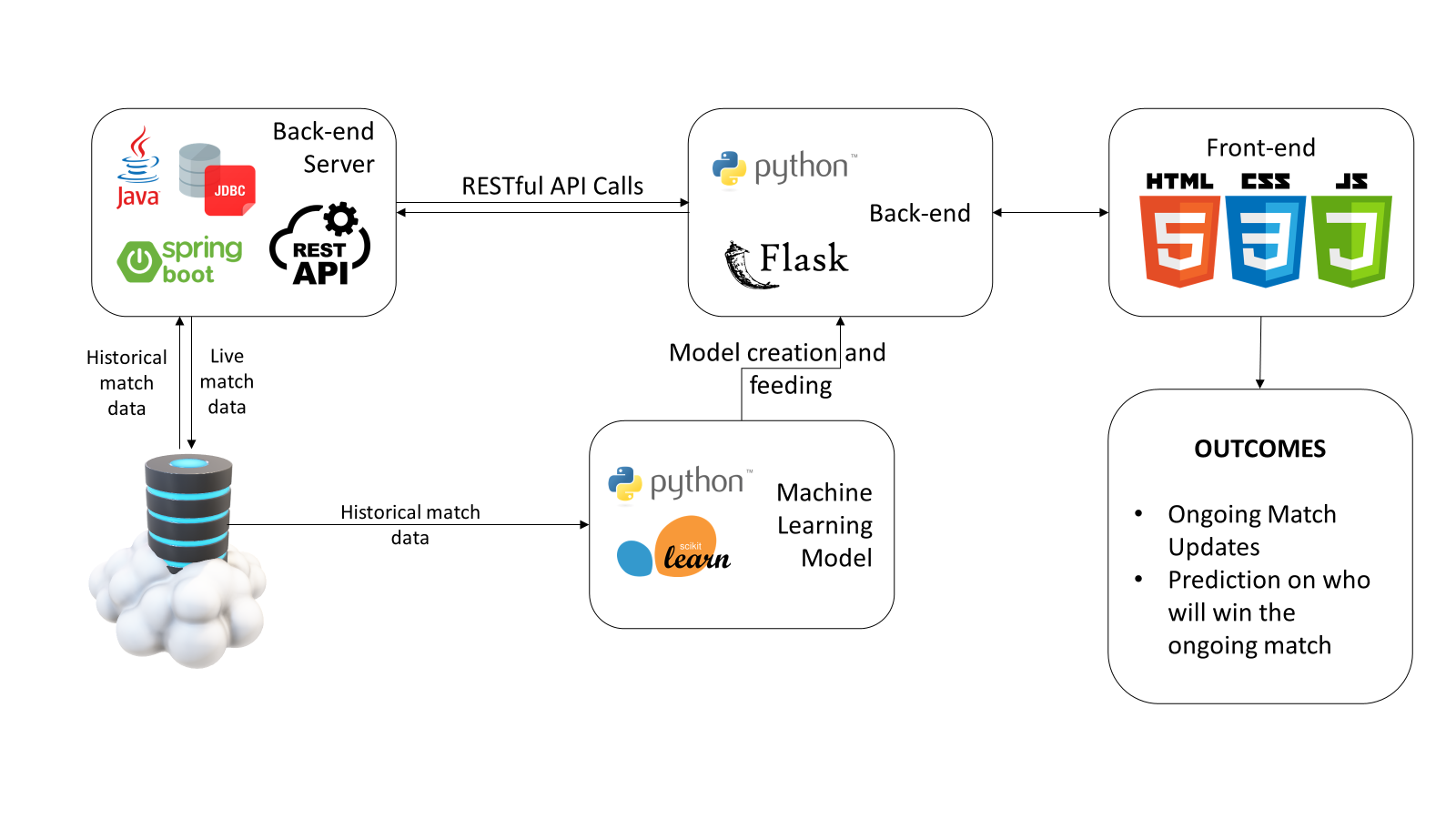
Implementation
Thank You

