Personal Data Detection - KG Competitors
INFO 523 - Spring 2024 - Project Final
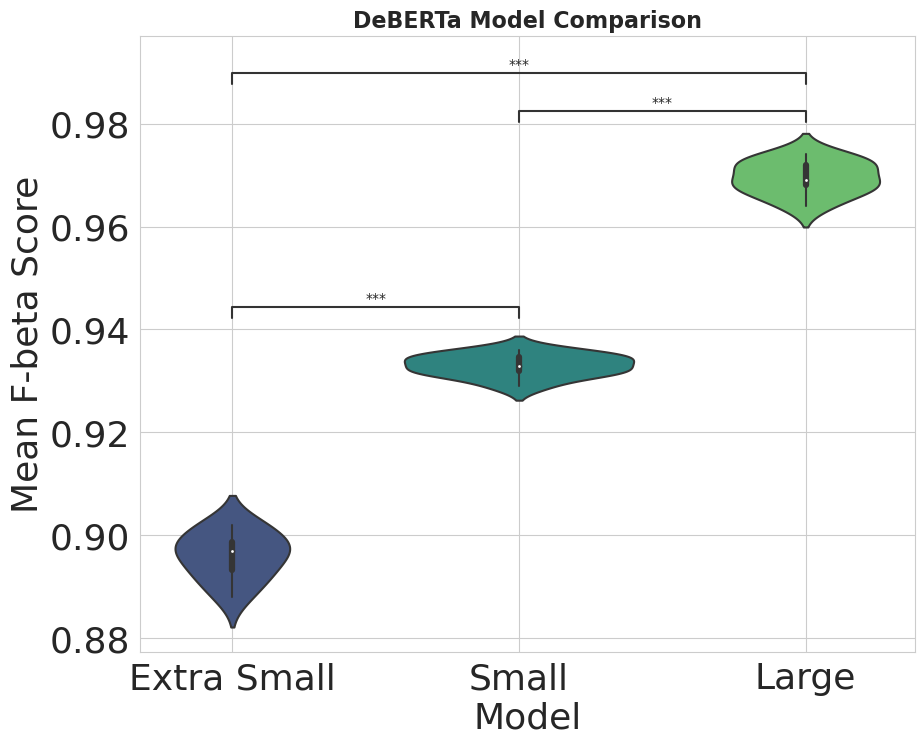
Results

References
- [1] Our Kaggle Competition Info can be found here: https://www.kaggle.com/competitions/pii-detection-removal-from-educational-data/overview
- For title page image: https://www.freepik.com/free-vector/fingerprint-concept-illustration_10258681.htm#query=personal%20data&position=49&from_view=keyword&track=ais&uuid=a14f34fb-adf2-45bc-a8f5-ae2b66197593
- Our logo: https://icons8.com/icons/set/competition
- Detect Fake Text: KerasNLP [TF/Torch/JAX][Train]
- Token classification
- Transformer ner baseline [lb 0.854]
- Thank You image: https://www.freepik.com/free-vector/thank-you-concept-illustration_34680609.htm#page=2&query=thank%20you%20gif&position=29&from_view=keyword&track=ais&uuid=e51f94e5-1758-47eb-8cb9-8d69209b8ffd
